I need a way to roll-up multiple rows into one row and one column value as a means of concatenation in my SQL Server T-SQL code. I know I can roll-up multiple rows into one row using Pivot, but I need all of the data concatenated into a single column in a single row. In this tip we look at a simple approach to accomplish this.
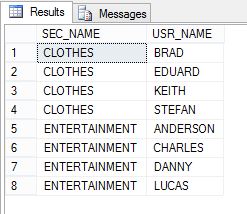
To illustrate what is needed, here is a sample of data in a table from SQL Server Management Studio (SSMS):
This is an example of rolling up multiple rows into a single row. This is what we want the end result set to look like:
SQL Server T-SQL code to create the above result set by rolling up multiple rows into a single row using FOR XML PATH and the STUFF function:
SELECT SS.SEC_NAME, STUFF((SELECT '; ' + US.USR_NAME FROM USRS US WHERE US.SEC_ID = SS.SEC_ID FOR XML PATH('')), 1, 1, '') [SECTORS/USERS] FROM SALES_SECTORS SS GROUP BY SS.SEC_ID, SS.SEC_NAME ORDER BY 1
Continue reading this SQL tutorial to learn about additional options and explanations for rolling up multiple rows into a single row.
Rolling up data from multiple rows into a single row may be necessary for concatenating data, reporting, exchanging data between systems and more. This can be accomplished by:
Check out the example below to walk through the code samples and final solution to roll-up multiple rows into a single row in SQL Server.
Before we begin, we'll create some tables and sample data which the following script will do for us.
CREATE TABLE SALES_SECTORS( SEC_ID INT, SEC_NAME VARCHAR(30)) GO CREATE TABLE USRS( USR_ID INT, USR_NAME VARCHAR(30), SEC_ID INT ) GO CREATE TABLE ADV_CAMPAIGN( ADV_ID INT, ADV_NAME VARCHAR(30) ) GO CREATE TABLE USR_ADV_CAMPAIGN( USR_ID INT, ADV_ID INT ) GO CREATE TABLE SEC_ADV_CAMPAIGN( SEC_ID INT, ADV_ID INT ) GO INSERT INTO SALES_SECTORS( SEC_ID, SEC_NAME ) VALUES ( 1, 'ENTERTAINMENT' ) INSERT INTO SALES_SECTORS( SEC_ID, SEC_NAME ) VALUES ( 2, 'CLOTHES' ) GO INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 1, 'ANDERSON', 1 ) INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 2, 'CHARLES', 1 ) INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 3, 'DANNY', 1 ) INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 4, 'LUCAS', 1 ) INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 5, 'KEITH', 2 ) INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 6, 'STEFAN', 2 ) INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 7, 'EDUARD', 2 ) INSERT INTO USRS( USR_ID, USR_NAME, SEC_ID ) VALUES ( 8, 'BRAD', 2 ) GO INSERT INTO ADV_CAMPAIGN( ADV_ID, ADV_NAME ) VALUES ( 1, 'SONY ENTERTAINMENT' ) INSERT INTO ADV_CAMPAIGN( ADV_ID, ADV_NAME ) VALUES ( 2, 'BEATS SOUNDS' ) INSERT INTO ADV_CAMPAIGN( ADV_ID, ADV_NAME ) VALUES ( 3, 'BOOSE' ) INSERT INTO ADV_CAMPAIGN( ADV_ID, ADV_NAME ) VALUES ( 4, 'POLO RALPH LAUREN' ) INSERT INTO ADV_CAMPAIGN( ADV_ID, ADV_NAME ) VALUES ( 5, 'LACOSTE' ) GO INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 1, 1 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 1, 2 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 2, 2 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 2, 3 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 3, 3 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 4, 2 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 5, 4 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 6, 5 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 7, 4 ) INSERT INTO USR_ADV_CAMPAIGN( USR_ID, ADV_ID ) VALUES ( 8, 5 ) GO INSERT INTO SEC_ADV_CAMPAIGN( SEC_ID, ADV_ID ) VALUES ( 1, 1 ) INSERT INTO SEC_ADV_CAMPAIGN( SEC_ID, ADV_ID ) VALUES ( 1, 2 ) INSERT INTO SEC_ADV_CAMPAIGN( SEC_ID, ADV_ID ) VALUES ( 1, 3 ) INSERT INTO SEC_ADV_CAMPAIGN( SEC_ID, ADV_ID ) VALUES ( 2, 4 ) INSERT INTO SEC_ADV_CAMPAIGN( SEC_ID, ADV_ID ) VALUES ( 2, 5 ) GO
Before going to the examples, we need to understand the workings of the commands mentioned above. The STUFF() function puts a string in another string, from an initial position. With this we can insert, replace or remove one or more characters.
This syntax is STUFF(character_expression, start, length, replaceWith_expression):
Here is an example of the how to use the STUFF command.
For our example we have a single string that looks like this:
;KEITH;STEFAN;EDUARD;BRADWe want to remove the first ; from the list so we end up with this output:
KEITH;STEFAN;EDUARD;BRADTo do this we can use the STUFF command as follows to replace the first ; in the string with an empty string.
SELECT STUFF(';KEITH;STEFAN;EDUARD;BRAD', 1, 1, '')And this returns this output as a concatenated string:
KEITH;STEFAN;EDUARD;BRADThe FOR XML clause, will return the results of a SQL query as XML. The FOR XML has four modes which are RAW, AUTO, EXPLICIT or PATH. We will use the PATH option, which generates single elements for each row returned.
If we use a regular query such as the following it will return the result set shown below.
SELECT SS.SEC_NAME, US.USR_NAME FROM SALES_SECTORS SS INNER JOIN USRS US ON US.SEC_ID = SS.SEC_ID ORDER BY 1, 2
If we take this a step further, we can use the FOR XML PATH option to return the results as an XML string which will put all of the data into one row and one column.
SELECT SS.SEC_NAME, US.USR_NAME FROM SALES_SECTORS SS INNER JOIN USRS US ON US.SEC_ID = SS.SEC_ID ORDER BY 1, 2 FOR XML PATH('')
In SQL Server 2017, the STRING_AGG function was introduced as a new option to rollup data. Check out these tips to learn more:
Now that we see what each of these commands does, we can put these together to get our final result.
The example query below uses a subquery where we are returning XML data for the USR_NAME from table USRS and joining this to the outer query by SEC_ID from table SALES_SECTORS. For each value from the inner query, we are concatenating a ";" and then the actual value to have all of the data from all rows concatenated into one column. We are grouping by SEC_NAME to show all USERS within that SECTOR.
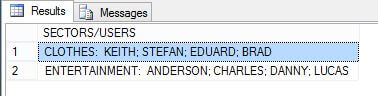
SELECT SS.SEC_NAME, (SELECT '; ' + US.USR_NAME FROM USRS US WHERE US.SEC_ID = SS.SEC_ID FOR XML PATH('')) [SECTORS/USERS] FROM SALES_SECTORS SS GROUP BY SS.SEC_ID, SS.SEC_NAME ORDER BY 1
The below is the output for this query. We can see that we have the leading; in the SECTORS/USERS column which we don't want.
In this modified example, we are now using the STUFF function to remove the leading ; in the string.
SELECT SS.SEC_NAME, STUFF((SELECT '; ' + US.USR_NAME FROM USRS US WHERE US.SEC_ID = SS.SEC_ID FOR XML PATH('')), 1, 1, '') [SECTORS/USERS] FROM SALES_SECTORS SS GROUP BY SS.SEC_ID, SS.SEC_NAME ORDER BY 1
And we get this result set:
If we also want to order the SECTORS/USERS data we can modify the query as follows:
SELECT SS.SEC_NAME, STUFF((SELECT '; ' + US.USR_NAME FROM USRS US WHERE US.SEC_ID = SS.SEC_ID ORDER BY USR_NAME FOR XML PATH('')), 1, 1, '') [SECTORS/USERS] FROM SALES_SECTORS SS GROUP BY SS.SEC_ID, SS.SEC_NAME ORDER BY 1
If we want this all to be in one column, we can change the query a little as follows:
SELECT SS.SEC_NAME + ': ' + STUFF((SELECT '; ' + US.USR_NAME FROM USRS US WHERE US.SEC_ID = SS.SEC_ID FOR XML PATH('')), 1, 1, '') [SECTORS/USERS] FROM SALES_SECTORS SS GROUP BY SS.SEC_ID, SS.SEC_NAME ORDER BY 1
And this gives us this result:
This example takes it a step further where we have multiple subqueries to give us data based on USERS within CAMPAIGNS within SECTORS.
SELECT SS.SEC_ID, SS.SEC_NAME, STUFF((SELECT '; ' + AC.ADV_NAME + ' (' + STUFF((SELECT ',' + US.USR_NAME FROM USR_ADV_CAMPAIGN UAC INNER JOIN USRS US ON US.USR_ID = UAC.USR_ID WHERE UAC.ADV_ID = SAC.ADV_ID FOR XML PATH('')), 1, 1, '') + ')' FROM ADV_CAMPAIGN AC INNER JOIN SEC_ADV_CAMPAIGN SAC ON SAC.ADV_ID = AC.ADV_ID AND SAC.SEC_ID = SS.SEC_ID ORDER BY AC.ADV_NAME FOR XML PATH('')), 1, 1, '') [CAMPAIGNS/USERS PER SECTOR] FROM SALES_SECTORS SS GROUP BY SS.SEC_ID, SS.SEC_NAME

Here is an example that will rollup indexes into one row and show the columns that are part of the index as well as included columns if any exist.
SELECT SCHEMA_NAME(ss.SCHEMA_id) AS SchemaName, ss.name as TableName, ss2.name as IndexName, ss2.index_id, ss2.type_desc, STUFF((SELECT ', ' + name from sys.index_columns a inner join sys.all_columns b on a.object_id = b.object_id and a.column_id = b.column_id and a.object_id = ss.object_id and a.index_id = ss2.index_id and is_included_column = 0 order by a.key_ordinal FOR XML PATH('')), 1, 2, '') IndexColumns, STUFF((SELECT ', ' + name from sys.index_columns a inner join sys.all_columns b on a.object_id = b.object_id and a.column_id = b.column_id and a.object_id = ss.object_id and a.index_id = ss2.index_id and is_included_column = 1 FOR XML PATH('')), 1, 2, '') IncludedColumns FROM sys.objects SS INNER JOIN SYS.INDEXES ss2 ON ss.OBJECT_ID = ss2.OBJECT_ID WHERE ss.type = 'U' ORDER BY 1, 2, 3
There are always several options to complete a task within SQL Server and we should take the time to explore the capabilities offered by the database before developing large and complex code. I hope this is one more of those examples that shows there are sometimes easier approaches than you think might be available.






Douglas Castilho has been a SQL Server DBA over 6 years, focuses on tuning, backup, disaster recovery, mirroring, T-SQL, PL-SQL and .NET
This author pledges the content of this article is based on professional experience and not AI generated.
Article Last Updated: 2023-10-25
| Thursday, April 4, 2024 - 3:15:00 PM - Gentre | Back To Top (92150) |
| Thanks a bunch! This performed exactly what I needed done and very efficiently. Very, VERY helpful! | |
| Wednesday, October 25, 2023 - 11:40:18 AM - Greg Robidoux | Back To Top (91709) |
| Hi Valeriy, | |
there is another article that talks about STRING_AGG
| Wednesday, March 22, 2023 - 3:44:47 AM - Valeriy Yagudin | Back To Top (91033) |
| Why didn't you include STRING_AGG? | |
| Tuesday, April 26, 2022 - 4:50:50 PM - Ash | Back To Top (90038) |
| Hello, | |
I'm trying generate payment advice message into 1 row right now it is showing multiple message lines.
This is code i'm using
%InsertSelect(RADV_DTL_TAO, PMT_INVOICE_TBL,RADVISE_KEY = C.PMT_ID, REFERENCE_FLD = A.INVOICE_ID, DATE1 = A.INVOICE_DT, PROCESS_INSTANCE = B.PROCESS_INSTANCE, CURRENCY_CD = A.PAID_AMT_CURRENCY, AMOUNT_1 = A.GROSS_AMT, AMOUNT_2 = A.PAID_AMT, AMOUNT_3 = A.DISCOUNT_TAKEN ,DESCR254 =substring(A.DESCR254_MIXED +CHAR(10)+D1.PYMNT_MESSAGE,1,254), PAY_DOC_ID = A.PAY_DOC_ID)
FROM PS_PMT_INVOICE_TBL A, ((PS_VOUCHER B1 LEFT OUTER JOIN PS_PYMNT_VCHR_MSG C1 ON B1.BUSINESS_UNIT = C1.BUSINESS_UNIT
AND B1.VOUCHER_ID = C1.VOUCHER_ID ) LEFT OUTER JOIN PS_PYMNT_MSG_LN D1 ON C1.PYMNT_MESSAGE_CD = D1.MESSAGE_CD
AND D1.PYMNT_MESSAGE <> ' '), %Table(PMT_STL_TAO) B , PS_PMT_DETAIL_TBL C , PS_PMT_SRC_DEFN D
ORDER BY D1.PYMNT_MESSAGE FOR XML PATH ('')
WHERE B.PROCESS_INSTANCE = %ProcessInstance
AND B.PMT_SOURCE = D.PMT_SOURCE
AND D.REMIT_ADVISE_OPT='Y'
AND A.PMT_ID = B.PMT_ID
AND C.PMT_ID = B.PMT_ID
AND B1.BUSINESS_UNIT = A.BUSINESS_UNIT
AND B1.INVOICE_ID = A.INVOICE_ID
AND B1.INVOICE_DT = A.INVOICE_DT
| Friday, April 8, 2022 - 5:04:04 PM - Greg Robidoux | Back To Top (89982) |
| Hi Dana, | |
you could look at PIOVT and UNPIVOT
| Friday, April 8, 2022 - 3:11:02 PM - Dana Shields | Back To Top (89981) |
| Excellent article. But how do you do the opposite? i.e. expand multiple values in a single row/column into multiple rows? | |
| Friday, April 8, 2022 - 3:07:33 PM - Dana Shields | Back To Top (89980) |
| Excellent article, Rolling up multiple rows into a single row and column for SQL Server data. | |
| Thursday, November 4, 2021 - 5:14:31 AM - D James | Back To Top (89407) |
| Excellent article, helped me solve a horrible report query I struggled with. Many thanks. | |
| Monday, November 1, 2021 - 9:26:17 AM - iraj | Back To Top (89390) |
| very good | |
| Friday, June 18, 2021 - 1:10:01 AM - Peter | Back To Top (88874) |
| Thanks so much, exactly what i need. Have previously used a heap of left joins and subqueries to achieve the same outcome, this is so much simpler and is dynamic. | |
| Tuesday, May 25, 2021 - 7:34:20 AM - Alexa | Back To Top (88735) |
| THIS HELPED ME A LOT | |
| Tuesday, May 25, 2021 - 7:32:54 AM - Alexa | Back To Top (88734) |
| Respected Sir | |
Here's a query I was trying to solve in mysql
roll subject grade
The required result is
roll math phy eng
| Wednesday, May 5, 2021 - 2:33:48 PM - Kaitlyn Nohrenberg | Back To Top (88650) |
| Hello, | |
This is the query I am working on, the goal is to have the correct locations for the individual part number but it looks like it is combining all the answers and every outcome is the same no matter the partnumber.
Select Distinct
PartNumber as 'Part',
Stuff ((Select distinct ', '+
Case When (a.Location like 'IM-%') then Stuff(a.location,1,3,'') else a.location end
From dbo.sublots as a
left join dbo.lots as b on a.LotNumberId= b.LotNumberId
left join dbo.parts as c on b.PartNumberId=c.PartNumberId
Where a.warehouse in ('Pr03')
and a.location is not null
and quantity > 0
For XML PATH('')), 1,2, '') as Location
From dbo.sublots as a
left join dbo.lots as b on a.LotNumberId= b.LotNumberId
left join dbo.parts as c on b.PartNumberId=c.PartNumberId
Where a.warehouse in ('Pr03')
group by PartNumber
order by PartNumber desc
| Thursday, March 11, 2021 - 2:35:15 PM - Greg Robidoux | Back To Top (88379) |
| Hi Paul, see if the concepts in this article would help you: https://www.mssqltips.com/sqlservertip/6315/group-by-in-sql-sever-with-cube-rollup-and-grouping-sets-examples/ | |
| Thursday, March 11, 2021 - 2:21:38 PM - Paul | Back To Top (88378) |
| My last comment did not display correctly. | |
It should be listed as results:
column 1: Crayons
Column 2:
Red
Yellow
Blue
Each color would be on its own row, and each row in column 1 after Crayons would be empty. Much like an excel spreadsheet would look.
| Wednesday, March 10, 2021 - 4:11:59 PM - Paul | Back To Top (88375) |
| Hello, | |
I am using Oracle.
This was helpful, in a sense, but I am trying to create a report that lists the data like this:
TABLE_NAME TABLE_NAME
CRAYONS GREEN
RED
YELLOW
BLUE
PAPER BLACK
WHITE
I have not been able to find the answer anywhere and have had some trouble even wording it correctly to ask it.
Any help with that one would be much appreciated.
| Tuesday, February 2, 2021 - 3:11:16 PM - Christian Henry | Back To Top (88139) |
| Thank you Mr. Castilho, very good! | |
Thank you so much. This was a perfect solution for what I needed to do.
1. The XML PATH does not need a GROUP BY.
SELECT SS.SEC_NAME, (SELECT '; ' + US.USR_NAME FROM USRS US WHERE US.SEC_ID = SS.SEC_ID FOR XML PATH('')) [SECTORS/USERS] FROM SALES_SECTORS SS ORDER BY 1
2. There is this great function from SQL 2017 and above: Simpler, more readable and less space for mistakes in syntax.
SELECT SS.SEC_NAME, STRING_AGG(US.USR_NAME,';') FROM SALES_SECTORS SS INNER JOIN USRS US ON US.SEC_ID = SS.SEC_ID group by SS.SEC_NAME
Your SQL has an error. It will encode the resultting data witht XML markup. For instance, < will outtput as <
Solve it by doing this (note the use of TYPE.value):
STUFF((SELECT '; ' + US.USR_NAME FROM USRS US WHERE US.SEC_ID = SS.SEC_ID FOR XML PATH(''), TYPE.value('.', 'VARCHAR(MAX)'), 1, 1, '') [SECTORS/USERS]
Here is an article that shows how to do this with STRING_AGG()
I do realize that this article was first published in 2013 but, since it has been replished again here in 2020, please be advised that STRING_AGG() is the way to go on later versions of SQL Server. Here's the link for the function. Example "D" is what you want. Example "C" is mislabled and isn't what you want.
1000135 10
1000135 9
1000135 9458
1000135 8
1000135 74
1000135 6
1000168 75
1000168 42
1000168 74
I am using the 2nd example query however, I can't get the desired output.
Kindly help with the same
The query i used is
SELECT SS.SM1, STUFF((SELECT '; ' + US.SM2 FROM #temp2 US WHERE US.SN2 = SS.SN1 ORDER BY SM2 FOR XML PATH('')), 1, 1, '') [Symbols] FROM #temp1 SS GROUP BY SS.SN1, SS.SM1 ORDER BY 1
I've a csv file which contains data with new lines for a single row i.e. one row data comes in two lines and I want to insert the new lines data into respective columns. I've loaded the data into sql but now I want to replace the second row data into 1st row with respective column values.
ID Name Department DOB State Country Salary
1 Mohammed IT 2019-08-12 Odisha India 2000
2 Dinesh CS 2015-06-19 Andhra India 2500
2016-03-08 Andhra India 3200
4 Mohan ME 2012-10-11 Telangana India 2080
5 Shankar AE 2014-04-17
Telangana India 3000
I want the output like:
ID Name Department DOB State Country Salary
1 Mohammed IT 2019-08-12 Odisha India 2000
2 Dinesh CS 2015-06-19 Andhra India 2500
3 Naveen CH 2016-03-08 Andhra India 3200
4 Mohan ME 2012-10-11 Telangana India 2080
5 Shankar AE 2014-04-17 Telangana India 3000
Does the query work in SQL Server Management Studio?
Not sure what version of SQL Server you are using, but you could also look at the new STRING_AGG function.
I am not able to get this to work. I need to put this select into the Envision Argos Report generator and it is erroring out there. So, I put it inthe Toad took and it doesn't like the FOR XML so, is there another way to do this? This is where it has to live so my hands are tied.
Here is my code:
select distinct
spriden_id,
sgbstdn_term_code_eff,
spriden_first_name,
spriden_last_name,
sgbstdn_styp_code,
(SELECT '/' + gorrace_desc
FROM gorprac, gorrace
WHERE spriden_pidm = gorprac_pidm
and gorprac_race_cde = gorrace_race_cde
FOR XML PATH(''))
from spriden, sgbstdn
where spriden_pidm = sgbstdn_pidm
and sgbstdn_styp_code = '1'
and sgbstdn_term_code_eff in (201750,201770,201810,201830)
order by 1,2
I have tried example 1. However, my data is not rolling up.
from Freight_Rules as fr
for xml path('')),1,1,'') as Freight_Rule
from Orders as o
group by o.LoadFrt_FrtRule_Key,o.Ord_Key
Excellent work with demonstrations. Your title is great also as I seriously didn't think I would find anything like this to help me out.
This really assisted me on getting Duplicated entries. Now I need to try and Merge the Duplicated entries into "one version of the truth"
PrimaryOrganizationID Name DuplicatedIDs
3645994 'Duplicated Organization' 2952208, 2954445, 3348152, 3356275, 3549114, 3645994, 3302925
Is there a way to generate an update script to update all duplicated issues with the primary ID across many tables?
Thank you very much, it helped me a lot.
Douglas - Thank you so much for your time and effort putting this information out here. Your examples are clear and easy to follow.
�I am using the below to get type of pets. If there is no Pet, I want 'N/A' to be displayed. How can I incorporate this into the below statement?
� STUFF((SELECT CASE WHEN COUNT(pp.sPetType) = 1 and pp.sPetIsServiceAnimal = 'No' then '; ' + '1 ' + pp.sPetType� ELSE � � � � � CASE WHEN COUNT(pp.sPetType) = 2 and pp.sPetIsServiceAnimal = 'No' then '; ' + '2 ' + pp.sPetType� + 's' ELSE � � � � � CASE WHEN COUNT(pp.sPetType) = 3 and pp.sPetIsServiceAnimal = 'No' then '; ' + '3 ' + pp.sPetType + 's' � � � � � END END END � � � � � FROM person_pet pp � � � � � WHERE t.hMyPerson = pp.hMyPerson � � � � � GROUP BY pp.sPetType, pp.sPetIsServiceAnimal � � � � � FOR XML PATH('')), 1, 1, '')[PetType]
�Thank you so much for your tip. This helped me:)
�This is a nice solution provided, much thanks to the author :)
There is another easy way to achieve these functionality. for eaxmple, the above Example 2 can be do in the following way to acheive the same output.
(SELECT STRING_AGG (US.USR_NAME, ';')
FROM USRS US WHERE US.SEC_ID = SS.SEC_ID) [SECTORS/USERS]
FROM SALES_SECTORS SS
GROUP BY SS.SEC_ID, SS.SEC_NAME
why it's error. in code for XML PATH ('')
Can u plz help to writ a query to get the follwing result shown in ex.b
Thanks a lot for this article it helped me out quite a lot!
This is a very good article. It helped me a lot.
Hello, am doing on machine trnasliteration for master thesis , so how can we combine if the user input string on text box and the character mappings stored on different rows the table. How i can concatinate and disply them?
Thanks for this code! Thanks to google as well as I typed "how to gather all information of a column to a one column" as I didn't really know what the logic I want is called. haha So the process is called roll up.
Thank you very much for this info!
Please help me with below condition.
I am having SectorName and UserName
SNO ID SECTOR_NAME USERNAME
1 101 Cloths AAA
2 101 Entertainment BBB
3 101 Drinks CCC
4 101 Cloths DDD
5 222 Cloths EEE
6 433 Entertainment FFF
7 101 Entertainment GGG
8 222 Drinks HHH
Required Result:
foR id 101
SNO CLOTHS ENTERTAINMENT
1. AAA,DDD BBB,GGG
This example works great for me, it rolls-up the file correctly.
I do however, need to set values for the merged fields (like an array) so the application that will use this file can determine how many appointments need to be sent to the customer. I've reviewed the articles and none of them can answer this question.
Thank you for the clear explanation -- it's helped me twice now.
Now my comment: The code as written removed the leading semicolon, but leaves a leading space in front of the concatenated string. To fix it, simply adjust the STUFF command telling it to cut off two characters:
Thanks a lot Sir!
Previously I really struggled to grasp how to implement this concept - finally with your post it makes sense.
I will say, I never thought I would what is discussed above; however, the above has helped to 'extricate me from several nettles of danger.' And, thanks for the detailed explanations.
I will confess to using 'STUFF and the XML portion without really what they did.
Hi there. Thanks for the tip. But I have just one issue. I am working on my thesis. Back to my problem, waht if I want to create multiple columns for Users. One column for SEC_NAME, and individual colums for SECTORS/USERS. For example, 1 column cell for Clothes, 1 cell for Keith, other 1 for Stefan, and so on.
SEC_NAME Sector1 Sector2 Sector3 Sector 4
Clothers Keith Stefan Eduard Brad
Entertainment Anderson Charles Danny Lucas
Well, hoping I could find answers. Thank you. :D
Doug, thanks for the tip, great stuff (no pun). I do have a slight issue maybe you could help me with. My query is not in the right order and I'm not sure how to fix it. So when my query runs, it gets 5 records like such:
workID cid comment
100 2 Test 2
100 3 Test 3
100 5 Test 5
100 4 Test 4
100 1 Test 1
So, I want to get the two most recent comments for record 100 into 1 field. But now I am getting cid 2,3 and NOT 4,5. Does that make sense? When I add the cid to the group by statement I get 6 of the same records. ARGH! Can you point me in the right direction?
Thank you for this very explicit, simple and effective tip.
It Solved my problems in a few minutes.
Great article. It helped me to perform my task I got from my boss today and he is enchanted with what I have done thanks to you!
several years later and this is still relevant. Thanks!
Your syntax has a problem, if the text data contains < or >:
UPDATE ADV_CAMPAIGN SET ADV_NAME = ' ' WHERE ADV_ID = 1
then your last query will return
<SONY> <!--> <ENTERTAINMENT> (ANDERSON); BEATS SOUNDS (ANDERSON,CHARLES,LUCAS); BOOSE (CHARLES,DANNY)
If you would replace the FOR-XML-lines by
FOR XML PATH('i'), root('c'), type
).query('/c/i').value('.', 'varchar(8000)'), 1, 1, '') [CAMPAIGNS/USERS PER SECTOR]
it would return the correct
(ANDERSON); BEATS SOUNDS (ANDERSON,CHARLES,LUCAS); BOOSE (CHARLES,DANNY)
instead (feel free to use varchar(max) if necessary).
The data returned for the xmlpath using stuff function returns a lenght of 45678 .
But if it is used in the xmlpath it is generating all the rows.
select a.col1,+',' from a
This returns all the rows.
select stuff((select a.col1,+',' from a
for xml path('')),1,1,'') as b
This returns 45678 lenght of data
could you help in resolving this issue
Thank you. It's exactly what I looking for. :)
would be nice to have people put very vanilla query using the functions they share. too much going on and someone like myself, newbie, needs to understand basics on it and how to use it plain and simple to take a column with multiple values and place it into one single cell (one column and one row) as the output with comma separation in the next step following.
greatly appreciate anything. thank you.
Excellent;
but this just in SQL Server Management Studio,
As for Visual Studio it also shows the name of the XML tag <> &
Thanks for your solution and taking the time for explaining this tip.
Fantastic explanation, thankyou!
You guide help me a lots !!
Thanks Douglas for this excelent guide! It's exacly what i was looking for!
Thank you Douglas for this tip,
I have been scouring the web on how to do exactly this. With no luck I gave up, months later while researching SQL stuff, I stumbled upon this link and it was exactly what I needed months ago. Now I have this knowledge under my belt all thanks to you. Thank you!
Thank you so much! It really helped me and that was what I was searching for. :) Have a nice day.
HI Douglas. This is a great code. Howevder, I get this error :
Conversion failed when converting the varchar value '; ' to data type int.
I've tried everything and still its not working.
I want for real number the stuff command works only for variables
This is exactly what I have been searching for weeks! Thank you. Works perfectly with SSMS.
Dear Author Castilho,
Thank you for your useful tips published online.
I have one simple question that is bothering me so much, since I am a physician and have no big experience in sql (not even small) .
I need to recover data from our web based database. There are multiple records with the same name (because we repeat experiments for the same subject, but each experiment is in a separate row), so there will be several rows concerning one person but containes different data. I need while exporting the data to have a single row for each record that contains all information.
I will copy to you the automated query generated by the interface:
SELECT patient.nom AS 'Nom', patient.poids AS 'Poids', biology.date_consultation AS 'Measurement date', biology.heure_GDS AS 'Hour', biology.timemesure AS 'Time of measurement (before hpx . )', biology.jour AS 'Day (J-7/J0 . )', biology.chk_blood_type1 AS 'Arterial Blood', biology.pCO2 AS 'pCO2 mmHg', biology.pO2 AS 'pO2 mmHg', biology.SO2 AS 'sO2 %', biology.Hb AS 'Hb g/dL', biology.Htc AS 'Htc %', biology.Na AS 'Na mmol/L', biology.K AS 'K mmol/L', biology.Ca AS 'Ca mmol/L', biology.Lac AS 'Lactates mmol/L', biology.Glu AS 'Glu (glycemia)', biology.chk_blood_type2 AS 'Venous Blood', biology.pCO2_vein AS 'pCO2 mmHg', biology.pO2_vein AS 'pO2 mmHg', biology.SO2_vein AS 'sO2 %', biology.pH_vein AS 'pH val abs', biology.Hb_vein AS 'Hb g/dL', biology.Htc_vein AS 'Htc %', biology.Na_vein AS 'Na mmol/L', biology.K_vein AS 'K mmol/L', biology.Ca_vein AS 'Ca mmol/L', biology.Lac_vein AS 'Lactates mmol/L', biology.Glu_vein AS 'Glu (glycemia)', biology.chk_blood_type3 AS 'Mixt Venous Blood', biology.pCO2_veinMix AS 'pCO2 mmHg', biology.pO2_veinMix AS 'pO2 mmHg', biology.SO2_veinMix AS 'sO2 %', biology.pH_veinMix AS 'pH val abs', biology.Hb_veinMix AS 'Hb g/dL', biology.Htc_veinMix AS 'Htc %', biology.Na_veinMix AS 'Na mmol/L', biology.K_veinMix AS 'K mmol/L', biology.Ca_veinMix AS 'Ca mmol/L', biology.Lac_veinMix AS 'Lactates mmol/L', biology.Glu_veinMix AS 'Glu (glycemia)', biology.date_consult_labo AS 'Measurement date', biology.heure_labo AS 'Hour', biology.timelabo AS 'Time of measurement (before hpx . )', biology.jourlabo AS 'Day (J-7/J0 . )', biology.NA_labo AS 'Na mmol/L', biology.K_labo AS 'K mmol/L', biology.Cl AS 'Cl mmol/L', biology.CO2_labo AS 'CO2', biology.Creatinine AS 'Creatinine µmol/L', biology.Uree AS 'Uree mmol/L', biology.Glycemie AS 'Glycemie mmol/L', biology.Lactates AS 'Lactates mmol/L', biology.Proteines AS 'Proteines g/L', biology.ASAT AS 'ASAT Ul/l', biology.ALAT AS 'ALAT Ul/l', biology.Bili_tot AS 'Bilirubine totale µmol/L', biology.Bili_conj AS 'Bilirubine conj µmol/L', biology.Bili_lib AS 'Bilirubin libre µmol/L', biology.Gamm_GT AS 'Gamma GT Ul/l', biology.Phosphatase_Alcaline AS 'Phosphatase Alcaline Ul/l', biology.Hemoglo AS 'Hemoglobine g/dl', biology.Hemato AS 'Hematocrite %', biology.Leuco AS 'Leucocytes -/mm3', biology.Plaquettes AS 'Plaquettes -/mm3', biology.TP AS 'TP (taux de prothrombine) %', biology.timeTP AS 'time TP (sec)', biology.timeTPtemoin AS 'time temoin TP (sec)', biology.TCA AS 'TCA (temps de cephaline active) val abs', biology.timeTCA AS 'TCA time (sec)', biology.timeTCAtemoin AS 'TCA time temoin (sec)', biology.INR AS 'INR (internation normalized ratio) val abs', biology.Ammo AS 'Ammoniemie µmol/L'
FROM patient, biology
WHERE biology.ID_patient = patient.ID_patient
--This is a great time saver and great code- thank you!
Dude you just increased my quality of life.